嗨,這篇會寫比較短,簡單闡述一下我在人文領域,特別是日本文學上對於利用電腦工具,甚至是AI工具閱讀論文的歷程與為什麼我不在這個專案上繼續進行。
TL;DR
我嘗試將PDF透過acrobat OCR,並以程式標註假名、用各式AI工具進行總結或翻譯,結果是不管是假名工具、AI工具都不足以應付論文的難度與深度,鑒於在文件處理上會花太多時間,效率比手動差太多,可能需要等真的很厲害的AI出現。現階段的工具我會建議用在語料處理,或是教育現場給學生用的學習單、改作業上。
前言
在這個段落中,我想講講我接下來的章節或包含什麼內容,如同上面所說的,我主要嘗試了幾天關於如何利用電腦工具加速論文閱讀,我嘗試了我想到的方法,接下來逐章說明,我嘗試的方法有:
- 使用 OCR 工具將論文整理成文字
- 使用自然語言處理工具,在文字上標註假名幫助閱讀
- 使用AI工具對論文進行快速總結或翻譯
這幾個步驟相信可以想像出一張蠻漂亮的藍圖,我們先用工具將論文轉換成文字,這就解決了電腦沒辦法處理PDF文字的問題,而後來我們使用自然語言工具,就可以把文字標註假名,這邊等於在閱讀論文上解決了很大的痛點是日文有很多對於中文母語者來說的難字,甚至是可以做進一步的查詢。最後我們用AI工具替論文總結的話,理論上就可以更好的理解這篇文章。
使用 OCR 工具將論文整理成文字
這邊我用的工具是 Adobe Acrobat,Acrobat 可以每個月花600多塊錢訂閱就可以取得,相對於一些買斷的日文OCR服務需要買斷,Adobe 的精度相當不錯並包含各式功能,這邊就沒有再嘗試其他的了,關於日文OCR工具網路上有相當多的討論,基本都圍繞在読取革命16、Adobe Acrobat、Google Docs這三家在比,我因為買斷的關係沒有用読取革命16,而且介面相當陽春,我看Amazon上的評價其實也都沒有給很多好評。但,據說這款是可以讀取假名標註的,Acrobat不行。
而 Google Docs 在使用上面並不是太直覺,他沒有直接給出一個OCR的窗口,而是必須透過圖片將PDF文件打開,整體操作非常麻煩,但精度還算不錯。
最後就直接使用了 Adobe Acrobat,整體的結果還不錯,但還是不如預期,要把一篇約13頁的PDF整理到幾乎沒有錯,花了我大概2-3小時進行。
| Acrobat 結果 | 播磨風土記揖保郡阿為山の条には、「品太天皇之世釦副生於此山、故号阿刷山」ともある。 |
|---|---|
| 正確結果 | 播磨風土記揖保郡阿為山の条には、「品太天皇之世紅草生於此山、故号阿為山」ともある。 |
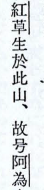
我們可以看到結果其實是相當好,但是對於一些日文特有的表記方法就很容易出錯,一連串的錯誤導致必須要很認真字字句句地看。且有另外一點很麻煩的是,Acrobat的OCR對於抓段落這點比較麻煩,他會很容易跳行,所以必須要用 alt 來整個框取,並把碎片的段落自己組合起來,這點也相當耗費時間與心力。
先不用講後面的內容,光是整理OCR的這些時間可能我都已經可以手動做完整篇論文的精讀了也不一定。
使用自然語言處理工具,在文字上標註假名幫助閱讀
在我們完成第一階段之後,我們就可以嘗試著利用整理好的文本來幫助我們理解這篇論文。為了更好的理解一篇「日文」論文,我們可以進行的動作有幾個
- 標假名
- 查單字
關於標假名,在這個過程中我嘗試用了一款日文的 NLP 工具,kuroshiro,這款工具可以切割句子的段落,並產出標假名的 ruby tag。
這邊只停留在 api-like 的使用階段,也就是輸入文字讓程式去跑,沒有進行全文的自動化。這個工具倒不是精度太低無法使用,而是處在跟上面同樣的情況,用工具的時間都足以自行查好很多單字,一些特別困難的字句也很難給出完全精準的翻譯,同樣必須手動進行調整。從下面的例子我們可以看到,像是色名應該是しきめい,而確例不知道為什麼確跑到上面了,但其他的都是正確的,還是值得鼓勵!

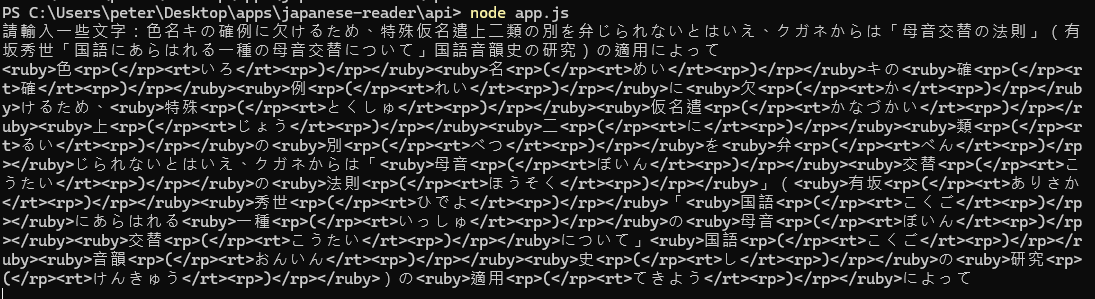
這邊分享一下我上面的 kuroshiro 的 cli app 的完整 code。其他的話官網都有完整說明,但在 package.json 裡面有一個地方要改。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import Kuroshiro from "kuroshiro";
import KuromojiAnalyzer from "kuroshiro-analyzer-kuromoji";
import readline from 'readline';
const kuroshiro = new Kuroshiro();
await kuroshiro.init(new KuromojiAnalyzer());
// use readline to get input from user
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
rl.question('請輸入一些文字:', async (input) => {
const result = await kuroshiro.convert(input, {mode:"furigana", to:"hiragana"});
console.log(result);
});
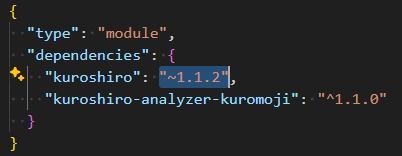
這邊改完 ~1.1.2 把版本降下去之後,重新跑一次 yarn install 應該就可以用了。網路上有不少說明,這是 demo code 寫錯的問題。
接下來是查單字,查單字就是相對比較棘手的,我們也要利用NLP的工具把字詞拆開,然後把字詞整理、丟到字典API裡面去做搜尋,但這個工序太繁瑣,又沒有那麼多字要查,直接打字到字典裏面反而比較快,就沒有進行了。
使用AI工具對論文進行快速總結或翻譯
這邊應該是網路上討論度最高的項目,我反而對這點興趣缺缺,我試了逐段總結跟翻譯,我覺得效果都不是很好,如果把整份文字檔餵給 chatGPT,他是沒有辦法完整閱讀完整份並給出一個適合的結論的,像是其他工具例如 gpt_academic,我覺得在設計上也不太適合這種資訊含量太大的文學類論文。我可能有朝一日讀電腦科學相關論文的時候再試試看吧。但目前為止的體驗很差。
就算是一段一段給 chatGPT,也很難掌握一個完整的藍圖,說真的不如用傳統的論文閱讀方法,老實地把前面後面看一看比較實際。這可能要等到之後 chatGPT 在能力上跟知識庫上有大幅度的進步,或是能一次性地輸入輸出大量語句的時候才有用處吧。
總結與展望
簡單寫了這篇文章講講目前電腦工具在閱讀日本文學論文上遇到的難題,基本上就是花的時間太多,而電腦能做的事情與準確度都太少,在閱讀論文上面,準確度要到幾乎不用修改並且有辦法提供專有名詞的讀音或註釋才有辦法為論文的閱讀上做出一點貢獻,AI工具也是同樣,現今的深度與精度都不太足夠,希望未來可以更加進步。
但這並不代表上面的作業是白費的,kuroshiro等NLP的整理除了可以做在機器學習上,標註假名可以幫助日文初學者快速地認識日文,而透過把句子拆開也可以提供學習者、甚至是語言學研究者更多的方向或是節省手動查詢語料細節的時間。
在閱讀論文上面 ai 沒有辦法提供太大的幫助,但就如同大家現在知道的,在翻譯、寫作、潤飾等等的項目上面ai都可以提供莫大的幫助,但在幫助輸入語言上面的話,我想還需要多加琢磨方向,我有看網路上的人是怎麼做的,但好像都沒有看到一個能夠說服我的論文閱讀方法,現階段還是老老實實地用眼睛看吧。
感謝閱讀! 本文同步發布於粉絲專業 PP學習筆記! 歡迎訂閱 YouTube頻道 與 追蹤粉絲專頁 PP學習筆記!